


Translating XML & HTML content
As types of mark-up language, XML and HTML are text files containing a mixture of content and information about the content (annotations or mark-up). HTML will typically be viewed in a browser and so has a mixture of text and formatting information to best present that text. XML is intended as a storage format or as a transfer format for data, and is made up of logical units of information.
Both formats are used extensively and need careful translation to ensure the translated versions still behave as intended.
Mark-up
XML and HTML are similar from a translation point of view in that they both have mark-up (whose special syntax must be protected) and text, some of which needs to be translated. Consider the following html example.
| Syntax | <td>The quick brown <i>fox</i> jumps over the lazy <i>dog</i>.</td> | |
| Browser View |
|
Inline Tags
The <td></td> syntax is less important for the translation because these markers sit at either end of the sentence; surrounding but not affecting the text. The <i></i> construct however, is referred to as a tag and in this case it is considered 'inline' because it appears within the body of a sentence.
| Syntax | <td>Le <i>renard</i> brun rapide saute par dessus le <i>chien</i> paresseux.</td> | |
| Browser View |
|
The difference between XML and HTML
HTML syntax is predefined. It is a known language for presenting data in a browser. The meaning of all elements and attributes is understood by both developers and browsers. If a developer wants a word to appear in italics, they would surround that word with an <i> </i> pair. If they want it to appear as bold, they would surround it with a <b> </b> pair.
This is not the case with XML. The browsers do not attribute meaning to the content in xml. Information is stored in xml as logical, self-explanatory units of data. It is not intended for display in a browser, so the markup does not define how text appears in a browser. Considering the following example, it seems to represent a person called A. Diamond who was born on the 6th Nov. 2000.
<person>
<name>A Diamond</name>
<date-of-birth>6th November 2000</ date-of-birth >
</person>
It was clear how to translate the html example earlier once we understood the meaning of <td> and <i>. The same is true here, if we understand what <person>, <name>, and <date-of-birth> are, then we can proceed.
Because XML is not a predefined format, a rule is needed to instruct Catalyst how to handle the different elements. Without instruction, the following translations would be likely
| Source | Target |
| A Diamond | Un Diamant |
| 6th November 2000 | 6th Novembre 2000 |
Of course, that is not what should happen. Instead, we need to indicate that the <name> element should be displayed for reference only. It should be protected, or locked somehow. In Catalyst, this is done using the ezParse feature. The user sees a flat structural representation of the document and can mark when pieces should be displayed, locked, treated as inline, etc.
A rule is created once and all xml documents following that format can be translated using that rule.
Alchemy CATALYST
HTML
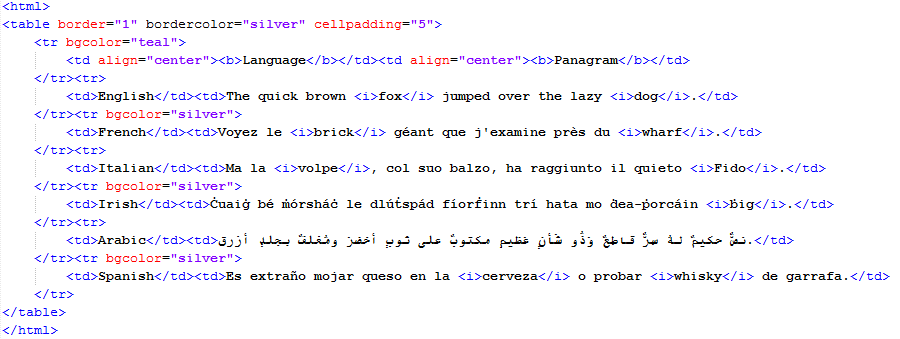
HTML syntax is predefined and understood by CATALYST, so no special handling needed. HTML is a native format in Catalyst. Like a browser understands what pieces to format and how, Catalyst understands what pieces of text to translate and what not to. The following html is displayed in CATALYST below. It is evident that editing the html code would be a very error prone task, while editing in CATALYST offers a secure translation environment.
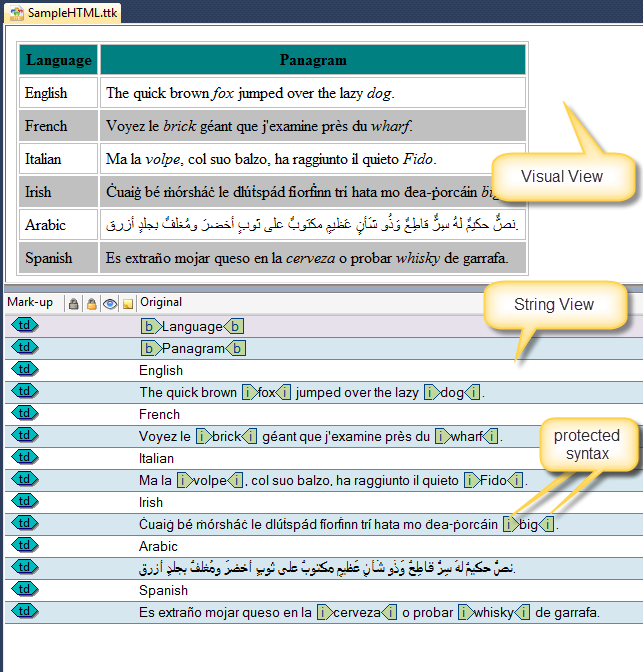
Customisable XML
From a translation point of view XML is different from HTML in that the syntax is not predefined. Each different type of xml needs a different rule. Depending on how a developer stores data, different units within the XML should be exposed for translation. The ezParse feature of CATALYST is used to create rules and define which pieces should be localized.
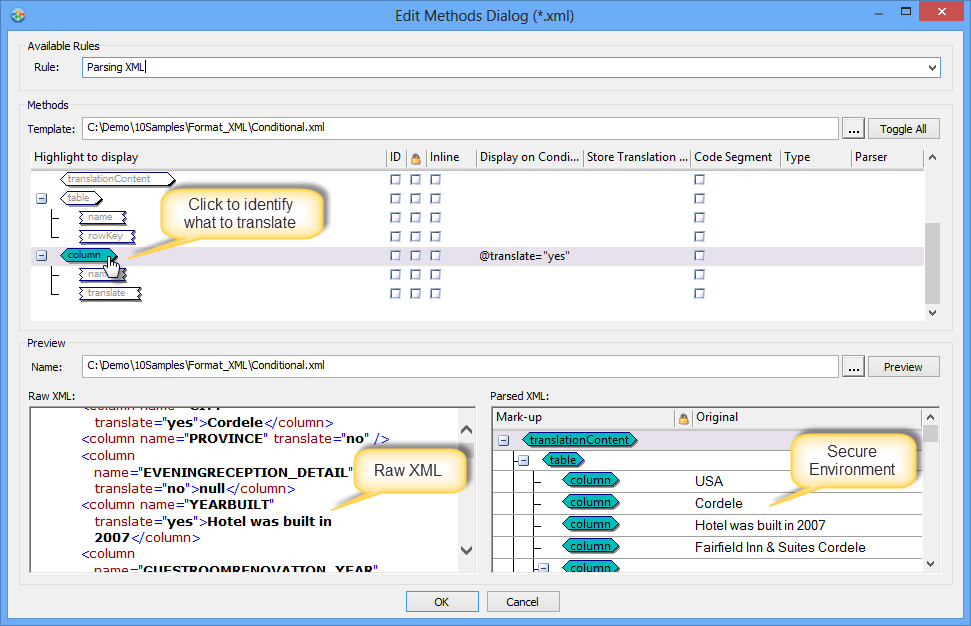
Inline Tags
We have seen already how inline tags are defined in code, how they are parsed and then displayed in Catalyst. The power of this solution comes from how simple it is to parse files but also in the security during editing of syntax as well as inline tag management.
Linguists translate the text segments with full access to translation memory, terminology, machine translation and validation features as well as full tag management capabilities.
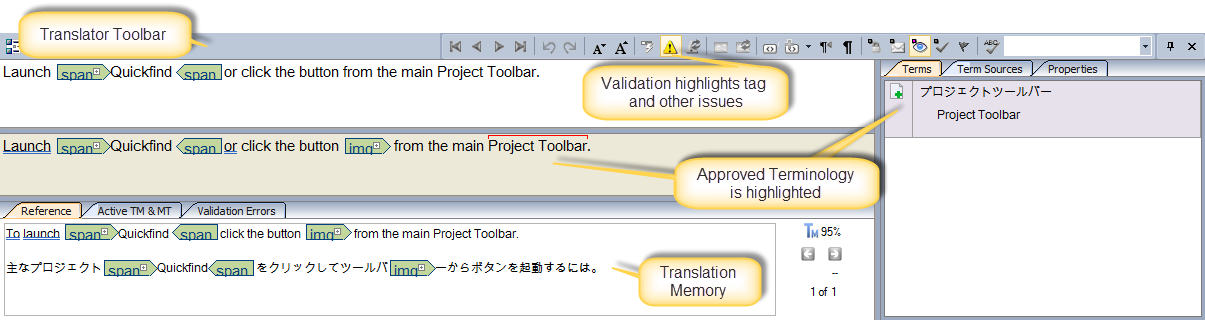
If tags are inadvertently removed or incorrectly edited, automatic validation indicates that to the user so the problem can be instantly corrected. Prevention is better than cure and while the Validation Expert is designed to identify problems after the fact, the Automatic Validation feature prevents errors being entered in the first place and saves time and money in the process.
Encodings & Entities
There are many ways to create the text files that make up XML and HTML files. Though there are many, popular encodings are utf-8 and utf-16. Other aspects that need special handling in a localization application are how special characters such as ©, ® & ™ are coded. These are known as entities and like inline tags need special handling. CATALYST ensures all of these more advanced topics are covered. The user need simply insert the file and translate - Catalyst looks after the separation of text and syntax.
Conclusion
Alchemy CATALYST provides a unified process for all file formats to be localized. Be they executable files, text files, source code, .net binaries, etc. or XML/HTML, a full feature set is provided to cater for all phases of the localization process. CATALYST support for XML & HTML is second to none in the industry and is a must in your arsenal if you deal with these file formats.
