|
|
|
Specifying IDs in XML parsing rules |
|
|
|
|
Specifying IDs in XML parsing rules |
|
IssueAs with all file types, parsing XML with unique IDs will improve the results of the Leverage Expert, maintaining ID-based translations, the Signed Off status and meta data (Locks, Memos, Context info). This article details the way IDs are defined in the parsing rules and the differences between using IDs or not. IMPORTANT: Leveraging with IDs will only work when the source files name is the same. In the below example, the file in the Translation Memory is ID order 1.xml and so is the updated file in the TTK we leverage into.
SolutionLet's take the following XML file which has 3 localisable strings nested in the same element. This is what we will call the original XML file.
This file is later updated resulting in elements listed in a different order within the file. We will call it the updated XML file.
The same source string is used in all 3 localisable elements. For example, "String" is a word which appears within 3 different sentences but has different translations depending on ID. This allows 3 different translations to suit internationalisation. In this article, it is to demonstrate the effects of identifying IDs where the same source string is translated differently.
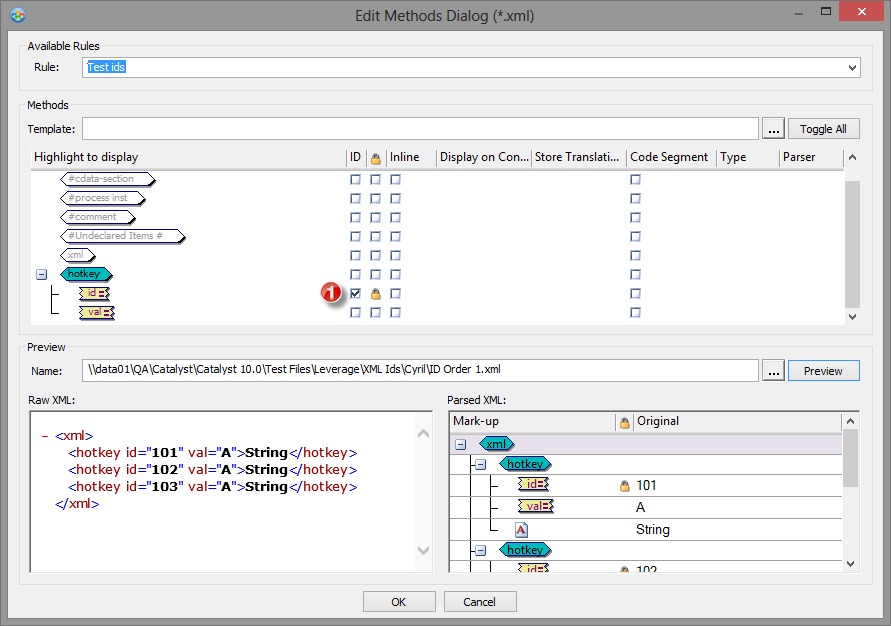
We created an XML parsing rule for the original XML file which specifies the id attribute as the ID of the string contained in the hotkey element. It's a good idea to also lock the ID to avoid over translation, see point 1 below.
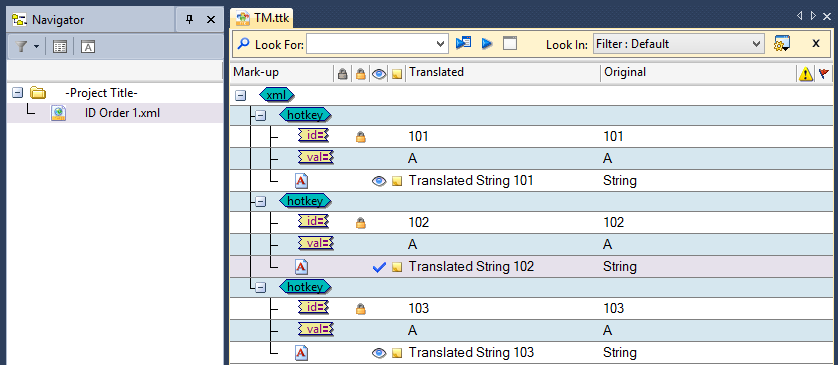
A TTK is created with the original XML file using the above "test IDs" parsing rules. Different translations are entered for the same source string. This TTK is named TM.ttk. It is important to note:
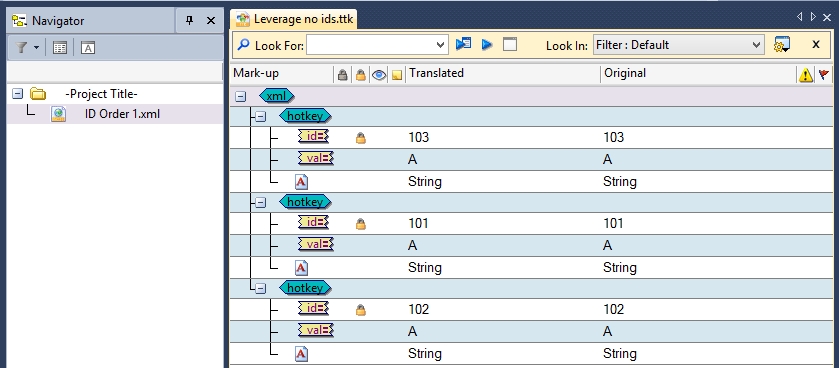
Now let's review the differences between leveraging our translations in the above TM (Translation Memory) into our updated XML file using IDs and not using IDs. Parsing the updated XML file without IDsCreating XML parsing rules without specifying the IDs will look like the following screenshot. The difference (as seen on point 1) with the parsing rules created with IDs is that the ID is ticked off for the id attribute, although left locked.
Inserting our updated XML file with this rule:
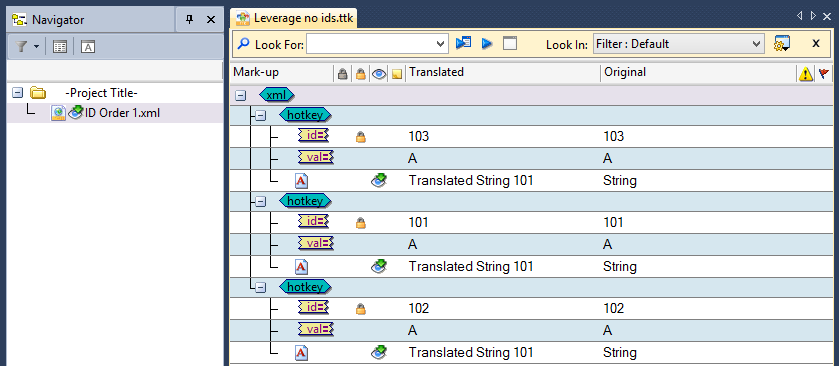
Leveraging from our TM.ttk, the same translation is applied to all instances of the source string "String"! See below. Further more the meta data and signed off statuses are missing. This is because, as the updated XML file has its element's order changed, and the parsing of the file has no ID to associate the translatable string with, Catalyst applies the first 100% match translation found in the TM for each instance of "String". A logical problem when no unique IDs are available.
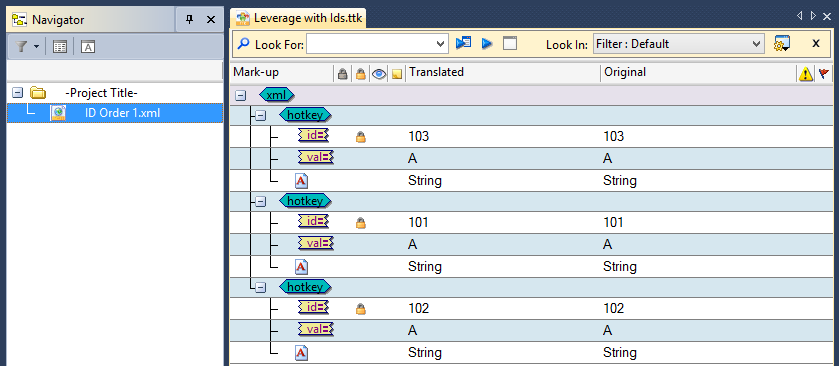
Parsing the updated XML file with IDsInserting the same update XML file in Catalyst using the parsing rules with ID (see first screenshot above), the TTK appears to be the same as when we inserted without IDs.
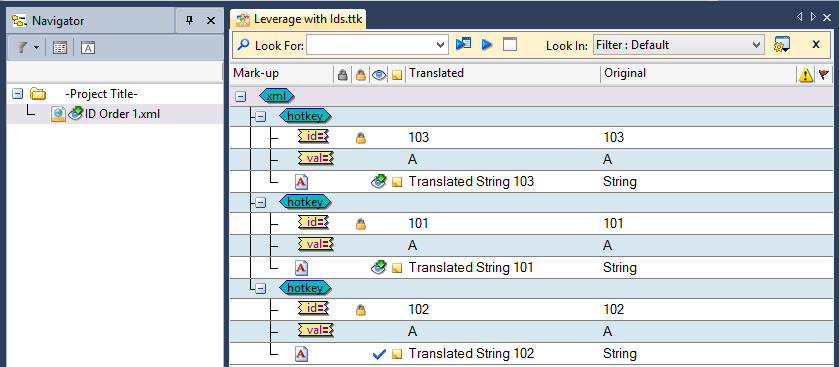
However, after leveraging the translations from TM.ttk, we find no loss of data and the translations accurately applied.
Related topics
Products or Versions Affected
Article last updated with Catalyst 10.0 on 18/07/2013
|
 |
 |
|
|