|
|
|
Parsing a Text File with String IDs and Context Strings |
|
|
|
|
Parsing a Text File with String IDs and Context Strings |
|
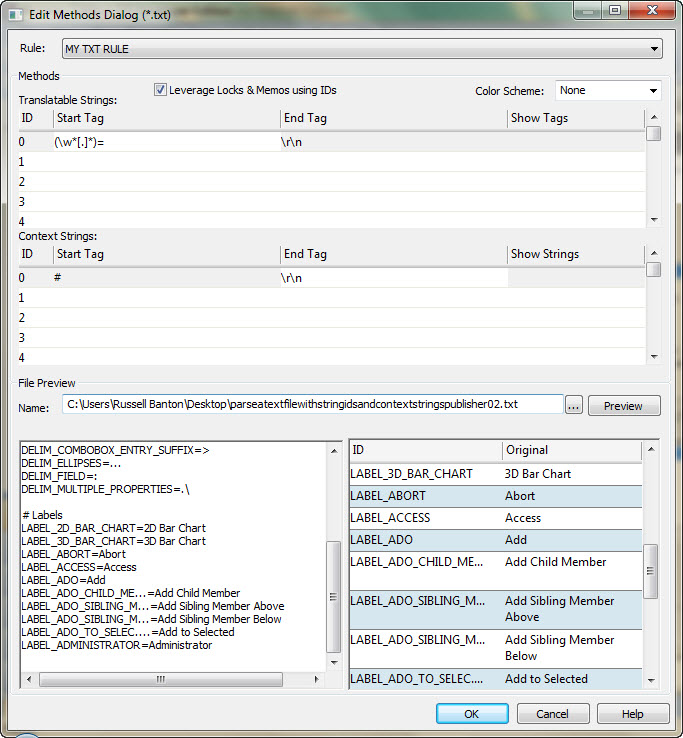
SolutionParse the String ID and the Localizable content out of the text fileCreate a new parse rule in Catalyst for the file that you wish to parse and open the file in the preview pane of the Catalyst ezParse UI. There is a link to the file in this example at the bottom of the document and you can try out the parse rule yourself if you like. 1. To begin with decide where the text you want to translate begins and ends. From looking at the text in the file you can see that the translatable text begins after the =. 2. This should now be added to your rule. You can also determine that the translatable text ends at the end of the sentence. So the end of the sentence is declared in the rule below as being the end of the text to be parsed for translation into Catalyst by the statement \r\n. 3. In this file you will also notice that every string that is to be translated has a unique String ID associated with it. 4. This string ID can be seen before the = in the file. The text that you wish to have as a string id is assigned as a string id by placing it in round brackets (). 5. In the file I am parsing all of the word characters before the = are part of the string id's that I wish to use. \w means word character and * means zero or more instances of a word character. 6. You will also notice some of the ids have "..." within them so [.]* needs to be added to represent zero or more instances of ".". 7. We now have \w*[.]* ass the part which is our string id so we put that in brackets, (w*[.]*). 8. This comes just before the identifier I have set as the start of my translatable string. With this in mind I can declare the (\w*[.]*)= as the string id which contains all the word characters and then ends at the = . This is where my text to be translated begins. Identify Text as Non Localizable that will never need to be TranslatedIn the text file below you will see that there are a lot of comments. These comments are there to explain what is happening in the code and these will never need to be translated. These comments are identified as all of the text that comes after the # character. Declaring this text as non localizable is much the same as declaring the other text as localizable. In the Context Strings section of the file is where these strings are identified. The start of these comments is always # in this file so in the context strings we declare this by typing # into the Start Tag. The end of these comments is always the end of the line in this file so in the context strings we declare this by typing a $ into the End Tag. String id's for Better LeveragingBy selecting the "Leverage Locks & Memos using ID's" in the ezParse rule you will see the benefit of declaring the String ID's. Along with these giving you a more accurate leverage by checking this box the Leverage Expert will be able to leverage locks and memos from your text file TTK's by matching the specified String ID's. Try this on the file from this ExamplePaste the content of the file I was parsing into a text file and name it as a *.properties file and then parse it using the rule I have created below. You should get the same results as me.
Click here to download file used in this FAQ.
Products or Versions Affected
|
 |
 |
|
|