

A new quarter, a new season and a new TechBytes newsletter. This time of the year has to be my favourite with all the vegetation blooming and the warmth of the summer slowly setting in. People are relaxed planning for their next BBQ and their summer holidays. And so am I! There is nothing more enjoyable than a sunny morning, walking to the Alchemy Headquarters in the centre of Dublin. Well okay, it's Ireland and it's not sunny that often, but don't go thinking it's always raining either ;-)
My picture on the left is actually a year old now and was taken on a boat trip we all took (the Alchemy team) in Dublin Bay. It was a nice relaxing day and a good way to recharge during the development of Catalyst 10. All this talk of sunny days got me to dig out this picture even though it wasn't warm at all on that day. At least not off shore!
I continue to take inspiration from queries we received from all of you avid Catalyst users and I came up with the following articles which I hope you will find very informative. It's all about exploring the depth of the application and optimizing its features to better translate your project, faster and efficiently.
Don't forget to let me know if you have any topic you would like covered in this TechBytes newsletter.
Cyril Vallin
Product Support Manager at Alchemy Software Development.
Catalyst 10 Service Pack 1 is out
The service pack (SP1) is now available for Alchemy Catalyst 10. This service pack can be applied to any build and any Edition of Catalyst 10. It is full with enhancements and fixes. Check out the details of those enhancements and fixes in the release notes.
If you download the full installer build of Alchemy Catalyst 10 today from our website, it will already include the SP1. It is build 100164. You can always check if there is a new build available in Help menu > About Alchemy Catalyst. There it will report if your installation is up to date. An internet connection is required.
Follow us on Twitter
Adding to our YouTube channel, I'm happy to say we have just launched our Twitter page giving you even more ways to keep up to date with developments. Click the Twitter button above to follow @AlchemySoftDev.Follow us on Twitter.
Many of you have several ANLM (Alchemy Network License Manager) servers across your organisation to distribute your various licenses. In some cases, a concurrent system is to safeguard against server outages, in others it is to allow one group's licenses need to spill over to another group when busy schedules demand it. Accounting for those reasons it makes sense to allow to get licenses from more than one ANLM server when available.
The ability to fall back on subsequent ANLM servers is possible using additional license files in the Catalyst installation. It couldn't be easier! No configuration is necessary on the ANLM servers themselves.
If you are using Catalyst with an ANLM server, you will be familiar with the license file required to get a license. Traditionally, the license file is named Client.lic and is located in the public folder:
• Microsoft Vista & Windows 7 = C:\Users\Public\Alchemy Software\Catalyst X.0
• All other Microsoft OS = C:\Documents and Settings\All Users\Alchemy Software\Catalyst X.0
This licence file contains the ANLM server name in that format:
SERVER server01 HOSTNAME=server01
VENDOR ALCHEMY
USE_SERVER
For each additional ANLM server you want to check for licenses, add a new client.lic in your Catalyst public folder. The key is to name the license files in the appropriate alphabetical order so that the first ANLM server is requested first, the second ANLM server is requested second and so on...
Example
You have 3 ANLM servers named server01, server02 and server03. You want your Catalyst 10 client to get a license from server1 first, then if no license are available query server2 and if still no license available check server03. No license available may mean that the server is down for any reason. To achieve this, 3 license files would be created in the Catalyst 10 public folder like so:
filename: Client1.lic
SERVER server01 HOSTNAME=server01
VENDOR ALCHEMY
USE_SERVER
filename: Client2.lic
SERVER server02 HOSTNAME=server02
VENDOR ALCHEMY
USE_SERVER
filename: Client3.lic
SERVER server03 HOSTNAME=server03
VENDOR ALCHEMY
USE_SERVER
When launching Catalyst, the software looks at the first .lic file in alphabetical order in the Public folder. This will be Client1.lic. If no license is available on this server or the server is down, Catalyst will move to the second .lic file in the public folder and look for a license on that server. And the process continues on until the last available .lic file.
This will work as long as all ANLM servers are on the same domain.
The concept behind the term "Conditional XML parsing" is the ability to define an XML Element as localisable only if one of its attributes matches a condition. A very clever way to accurately markup the contents of your XML files for localisation. Let's take an example.
This sample XML file is just a tiny section of a larger file destined for translation. The development team have included a translate attribute for each element in order to declare if the entry should be translated or not. This attribute is set to either "yes" or "no".
<?xml version="1.0" encoding="UTF-8"?>
<translationContent>
<table rowKey="3005844" name="Hotel">
<column name="PETSPOLICY_DETAIL" translate="no">null</column>
<column name="COUNTRYDISPLAYNAME" translate="yes">Ireland</column>
<column name="CITY" translate="yes">Dublin</column>
<column name="PROVINCE" translate="no">Leinster</column>
<column name="EVENINGRECEPTION_DETAIL" translate="no">null</column>
[...]
Normally, while setting up your parsing rules, you would select the column element as translatable by double clicking the element in the list (it turns turquoise) and click Preview to review the results.
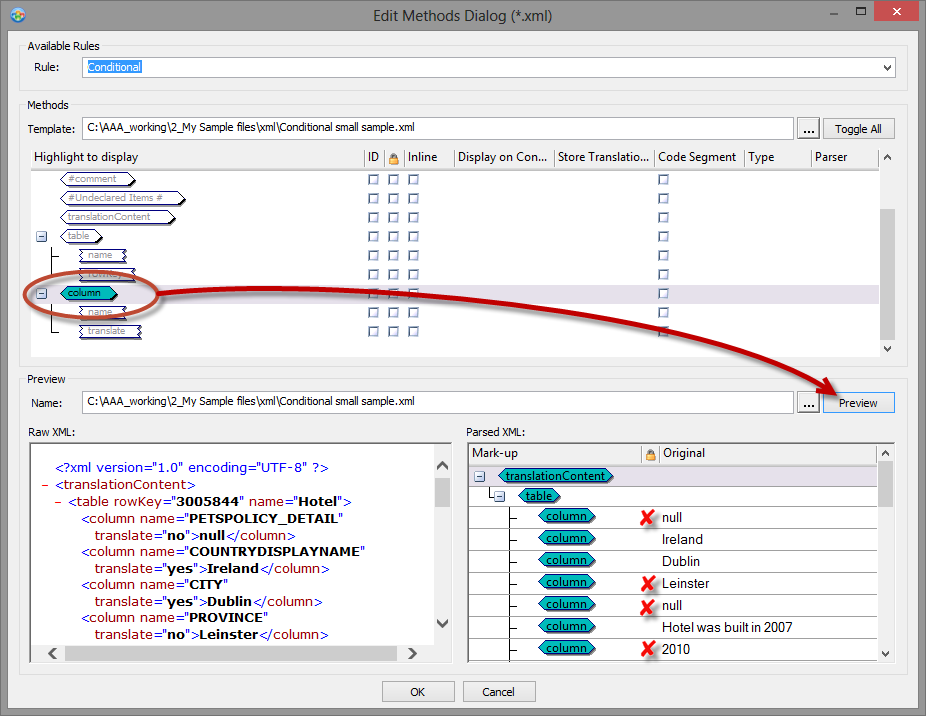
This as you would expect results in taking all text contained in the column element as localisable. And you will instantly realise that elements with attribute translate="no" are included in the string list.
This is where conditional XML comes in. You can define your parsing rules to only parse the string as localisable if the attribute translate has value "yes".
Enter @translate="yes" in the "Display on condition" column in the parsing rules and click Preview.
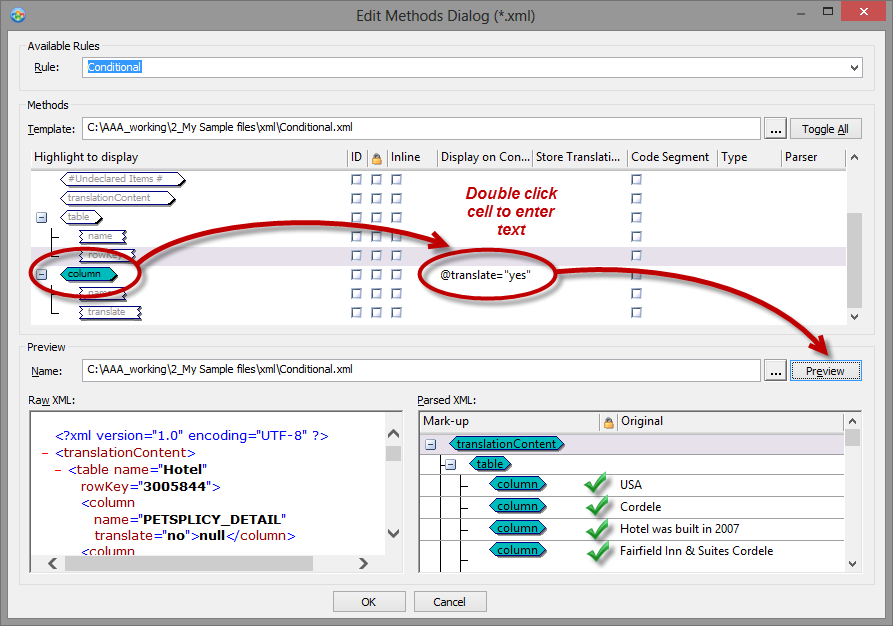
Now the string list only contains the strings which were intended for translation. Any Column element which does not have the attribute translate="yes" is omitted by the parsing rules.
Hint: if you actually only declare an attribute name in the condition, all elements with the attribute present will be localisable, regardless of its value.
For example, if you enter @translate as a condition, any column element with the attribute translate will be parsed as localisable.
But this isn't the end! We can complicate things a little and go further with conditional XML :-)
Using the sample file, try the different options below to see the results. Note that conditions are case sensitive.
Parent element
Using the ../@translate or ../@translate="yes" we can parse the string in the current element only if the parent element contains the attribute translate or translate with value yes respectively.
You'll have guessed this can go up several parent levels adding ../ for each level. ../../@translate="yes" with check for the translate attribute 2 parents up.
Try ../@translate="yes" with the sample file.
You will get 2 strings for translation (Free; Charged).
Not operator
This option is very useful because in great logic if you can define a rule to parse a string if a condition is met, then you should be able to parse any string unless a condition is met.
Use not(@translatable) or not(@translatable="false") to parse all strings which do not have attribute "translatable".
Try not(@translatable="false") with the sample file.
All strings will be parsed apart from the 3 strings with attribute translatable="false" (89387423, 34230989 and 34478989).
Or operator
Enter
@translate="yes" | not(@translate) you cover both options and will parse all localisable strings.
Beware that the spaces around the pipe symbol ‘|’ are not optional – leaving them out causes the ‘|’ to be taken as part of a normal XPath expression.
It is also possible to write the condition using "or" instead of "|"as @translate="yes" or not(@translate) Again spaces are not optional.
More interestingly, since the conditions are case sensitive, with the "or" operator you can combine different forms of the same condition like so:
@translate="yes" or @translate="YES" or @translate="Yes"
Try @translate="YES" or @translate="Yes" with the sample file.
You will get 2 strings for which the attribute is case matching (Alchemy says Yes, Catalyst says YES).
And operator
The last option available in conditional XML parsing rules is the and operator. With it, you may link more than one condition.
Enter @name="ATTOR" and @translate="yes" parse a string only if the attribute "name" with the value defined in the quotes AND the attribute "translate" with the value defined in the quotes. Again beware that the spaces around and are present, they are not optional.
Try @name="ATTOR" and @translate="Yes" with the sample. You will find only one string matches the condition (Alchemy says Yes ).
Warning! When copying and pasting conditions from a rich text editor, the quotes symbols may be converted to the stylised version of the quote which will not work in the Catalyst parsing rule.
You are, I am sure, well used to the predictive text on your mobile phone. Did you know that this feature is actually present already in Catalyst!
ezType is a predictive-text technology that can help translators to speed up their translation work process. It is turned on in the Translator Toolbar by clicking on the little lightning icon.
![]()
When the feature is activated the button will appear slightly yellow and Catalyst is monitoring what the translator is typing. Comparing the text entered with the Terms from the Glossary, the translations matches in the Active TMs and the original source text, in that important order. When a possible match is found, Catalyst will present an auto-completed word or sentence.
In the below screenshot the highlighted text is an auto-completed suggestion from the Glossary.

If the translator is happy with the suggested auto-completion, he or she can just use the arrow key -> to accept the suggestion.
However, if the suggestion is not correct the translator can just continue typing.
Segmentation refers to rules used to split a paragraph into individual segments or translation units. Segmentation occurs on parsing the file, meaning when you insert it in a project, and is only applied to HTML and XML files. No other file format is segmented on insertion.
With breaking large paragraph into sentences, you increase the potential re-use of your translations.Take for example, a paragraph made of 3 strings, say 20 words each. If not using segmentation, the paragraph is parsed as one string of 60 characters, while if segmenting the paragraph is split into 3 strings of 20 characters. Now assume that the file is updated to cover a spelling mistake made in the middle sentence. When leveraging the translations, in the case of not segmenting you will have a string of 60 characters marked untranslated, while with segmentation only one string of 20 characters will be unstranslated. I'll grant you that it is not such a disaster is you leverage fuzzy matches but you get the point ;-)
You can see the advantage of segmentation if you picture a different scenario where you are trying to re-use translations from a different project. The smaller the segments/strings, the higher the chances of a match compared to large strings.
By default, Alchemy CATALYST uses predefined neutral segmentation rules which are applicable to most languages. However, segmentation rules can also be created for specific source languages. Therefore you can optimize the segmentation to suit any given source language at your organisation.
You can configure segmentation under Tools > Options > Segmentation.
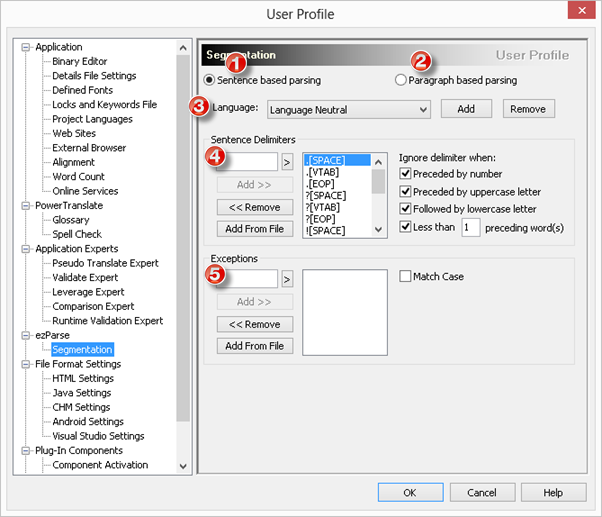
1 - Sentence based parsing
This option will enable all current Segmentation Rules and detect end of sentence punctuation (e.g. full stop, question mark) to segment files on insertion. Translation units will generally consist of complete sentences, increasing the accuracy and re-use during leverages.
2 - Paragraph based parsing
With this option Catalyst will ignore end of sentence punctuation and store complete paragraph objects. It is simply turning off segmentation.
This can be useful when aligning two translations that have significant differences in structure and format.
3 - Language
Segmentation Rules can be created for a specific language or for all languages. If you do not want to create Segmentation Rules specific to only one language you can leave the default setting Language Neutral. Alternatively, click the Add button to create a new language and define it's segmentation rules.
4 - Sentence Delimiters
Here you can add or delete Segmentation Rules. I find the default settings are fairly comprehensive but should you find a need to add or remove any rule, this is the place to do so.
5 - Exceptions
Abbreviated words or anagrams may occasionally cause the segmentation engine to misinterpret an end of sentence punctuation. To avoid this you can add exception rules. More on this below.
Managing exceptions
Once you have inserted your files for localization it is best to check for any segmentation issues.
A good example below shows how Catalyst applied a segmentation rule after the i.e. and therefore split the sentence into 2 segments.

To avoid the split into 2 segments we can add the following exception to the Segmentation rules:
i.e.[SPACE]
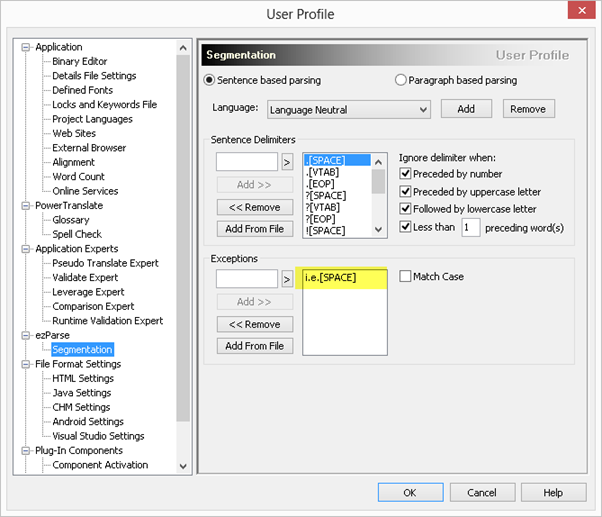
This exception will tell Catalyst to ignore the full stop after e if it is preceded by an i. and followed by a space after e., if you only added e.[SPACE] Catalyst would have ignored all sentences that end with e.

Changing segmentation rules
It is very important to set the segmentation rules at the beginning of the project and not change the rules in mid project. Doing the latter would impact negatively on TM accuracy, reuse and discovery. As pointed out earlier, changes in the way strings are parsed into a TTK will affect the result of your leverages.
For example I have changed the segmentation in the new HTML version but I want to use a TM that used the old segmentation rules.
The screenshot below shows how the translation did not match during the Leverage Process as the once 100% match is now decreased to a 76% fuzzy match. What was once 2 strings, is now just one.
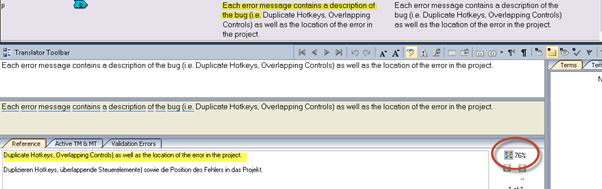
If different projects require different segmentation rules, remember you can save the segmentation settings in Tools menu > Options > User Profile. This way you can load the relevant segmentation rules for the project worked on.
Thanks for taking the time to read this installment of TechBytes. It has been fun to write and I hope you found some if not all of it beneficial. We always welcome new article ideas, so if there is a feature you feel works really well and is worth mentioning, or indeed if clarification on a particular topic would help you, please let me know so together we can make TechBytes as useful as possible for everyone.
My best wishes
Cyril Vallin
![]()