|
|
Create an Advanced ezParse Rule |
|
|
Create an Advanced ezParse Rule |
Select File Types & Parsing Rules from the HOME ribbon.
From the Configurable Rules File groups list control, select Text Based Files. Select .txt from the File extension list, then select Add from the Rules section.
Type ID Based rule when requested to enter a name and press OK.
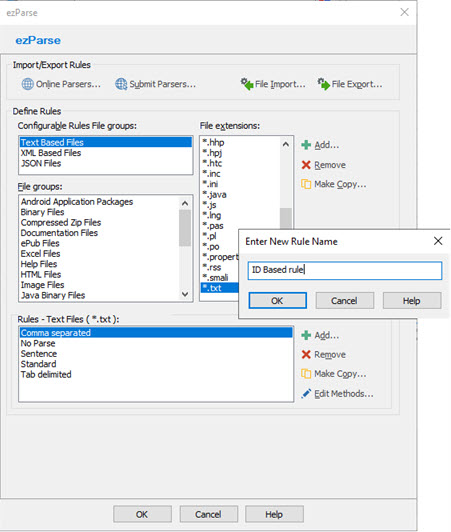
Now that you’ve created a Rule called ID Based rule, double-click it, or highlight the rule and select Edit Rule.
In the resulting dialog, we want to enter a value for the Start Tag and one for the End Tag.
The Start Tag expression we wish to add is ^([^= ]*) = " (see below for an explanation)
The End Tag should be "
|
Syntax |
Description |
|
^ |
This is the regular expression syntax for the beginning of a segment |
|
[^= ] |
The square brackets indicate a range of characters. The ^ inside the square brackets indicate a range of excluded characters. i.e. read this as any character excluding an equals or a space. |
|
[^= ]* |
The asterisk indicates any number of times. i.e. read this as any number of characters excluding an equals or a space. |
| = " |
This matches simple text space, equals, space, followed by a double quote. |
| ( ) |
Brackets are used to treat multiple syntax as a group. |
 While editing the Start and End tags, Right click the field to access the context menu which includes an optional list of common regular expression with their explanation.
While editing the Start and End tags, Right click the field to access the context menu which includes an optional list of common regular expression with their explanation.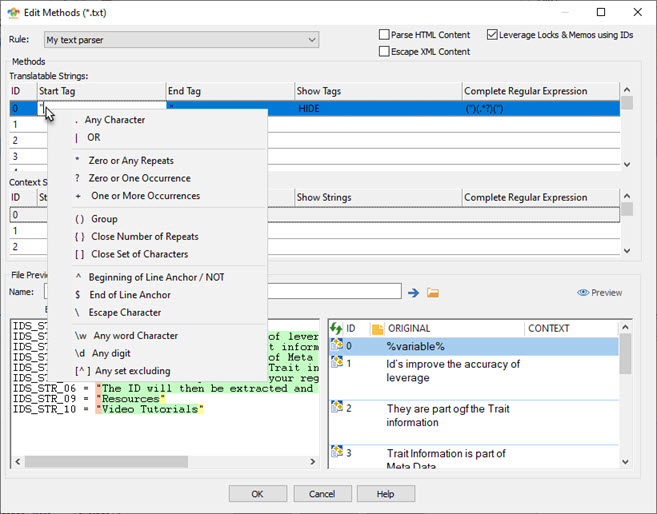
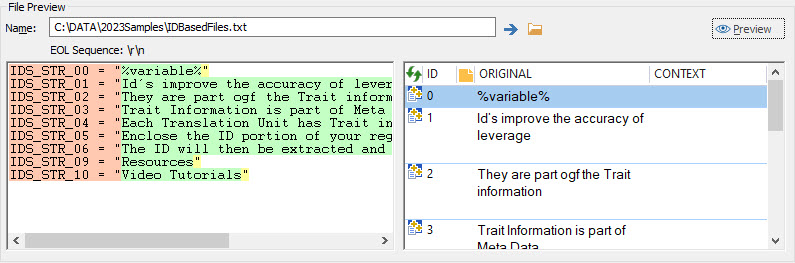
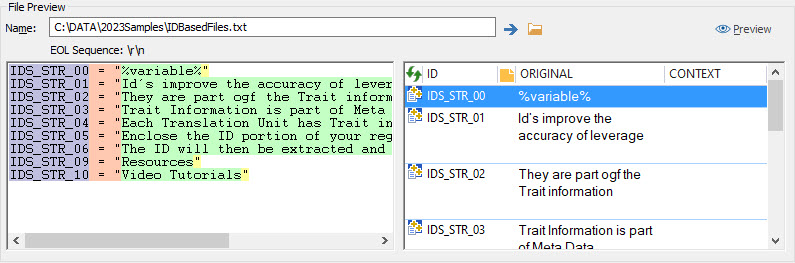
In the File Preview section, browse to the file IDBasedFiles.txt and press Preview.
The salmon colour code indicates a section of text identified as the Start Tag. The green colour code indicates the localizable text and the yellow colour code indicates the End Tag.
The next step is to set the ID. The pink colour coded text contains the ID. To indicate to CATALYST which part of the StartTag is the ID, click on the Complete Regular Expression
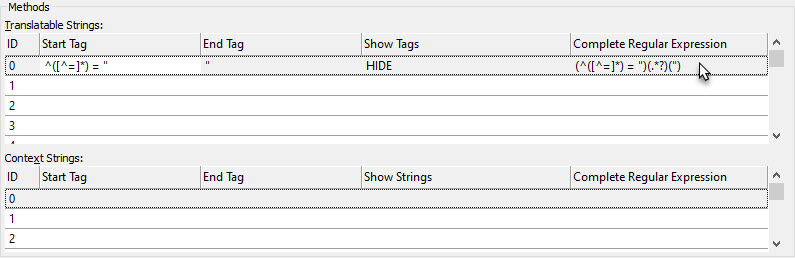
In the resulting dialog, check the option Segments have IDs and cycle through the numbers to see the effect of changing this value. The ID can be anywhere in the complete Regular Expression.
i.e. it could be
part of the Start Tag,
part of the Localizable Text,
part of the End Tag.
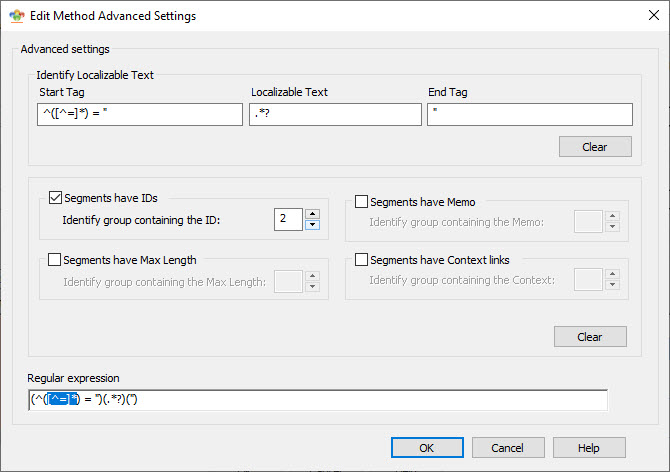
It is also possible to parse Memos, Maximum Length values and Context links identifying portions of the regular expression in brackets.
Just like identifying the ID, tick the Segments have Max Length and/or Segments have Memo and/or Segments have Context links checkbox and select the parentheses pair which includes the relevant regular expression.
Press OK to exit the Edit Method Advanced Settings dialog
Press Preview to ensure that rule has behaved correctly. The purple colour coding indicates the piece of the segment that has been identified as the ID
|
|
The preview of the original file is colour coded to help debug ezParse rules. A different colour is used for each element in a matching rule so you can easily spot when rules mismatch content in your file. Purple coded text represents the ID Pink colour indicates the Start Tag Green is the localizable text Yellow is the End Tag |
The ezParse rule is now complete and can be used to extract text from any file with a similar format. Press OK to close the Edit Methods dialog and OK again to save the rule on your machine.
3 additional options are available when defining your Text parsing rules.

Select to treat the localizable text (the text highlighted in green in the Preview) as HTML code. This means that HTML tags will be parsed as inline tags. For example, <B> or
This is particularly useful if you know the contents of the file is HTML based, allowing you to protect inline tags and give context to translator users.
Similarly to the above, use this option to treat the localizable text as XML code and thus escape any elements to its text representation.
Using the Escape XML contents option in text parsing rules converts all XML entities. This protects from over translation and makes it easier for users to translate.
Conversion happens in this order. The order is important because on parsing the file, CATALYST first converts
|
> |
> |
|
< |
< |
|
" |
“ |
|
' |
‘ |
|
&#dd; |
Where dd is a number in decimal format Example -> Newline Example -> Newline Example > -> > |
|
&#xnn; |
Where nn is a number in hex format |
|
& |
& |
And when extracting the file from CATALYST, the reverse substitution order is applied.
Treat any leverage of translations into files parsed using this option as only possible using matching IDs.