|
|
Scheduled Analysis |
|
|
Scheduled Analysis |
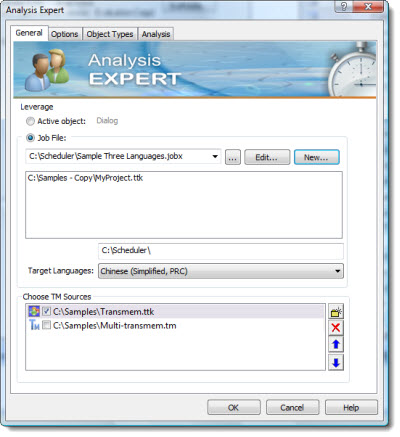
Scheduled Analysis uses a Job File and analyses one or more projects by comparing them to multiple translation memories to calculate the number of segment identical and fuzzy matches. A word count report is created using this Expert. This report can then be used by the project manager and/or translator to create a time line and costing for a translation project.
|
|
Job File |
|
|
Select this option to use the Scheduler and run an Expert in the background on your desktop PC. |
|
|
Edit |
|
|
Click this option to Edit the contents of a Job File. |
|
|
New |
|
|
Click this option to create a new Job File. |
|
|
Job Location |
|
|
This displays the target location for files processed by the Scheduler. |
|
|
Target Languages |
|
|
This displays a list of target languages that will be processed by the Scheduler. |
|
|
Choose TM Sources |
|
|
Define the TMs that are to be used for this analysis here. |
You can track the progress of the Analysis Expert using the Scheduler main window.

When the analysis completed, click on the View Report option in the Schedule main window to see the results.
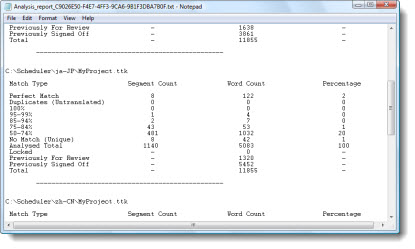
This Report displays the analysis results of every file as it goes through the Analysis process. At the bottom a summary report is provided that breaks the analysis down across several fuzzy-match categories. These categories are:-
|
Category |
Description |
|
Perfect Match |
This is the highest possible match from a TM. It arises when the source segment is identical to the text in the TM and the context in which the source segment is used is also matched in the TM. |
|
Duplicates (Untranslated) |
This is the count of the number of untranslated duplicates segments in your Project TTKs. Only the first occurrence of a duplicated segment is included in this figure. |
|
100% |
This is a match when the source segment is an identical match to text in a TM but it's context may differ. Generally, these segments will need to be reviewed and their translations verify by a senior translator or editor. |
|
95%-99% |
This is a range of non-identical matches that have been found in the GM. The higher the percentage value the more accurate the match in the TM. |
|
Locked |
This is the count of segments that are in the Project TTKs but are locked. They are not included in the Total words or any other fuzzy match count. |
|
Previously for Review |
This is the count of words that are already translated in the Project TTKs and are marked for Review. Generally, these segments will need to be reviewed and their translations verify by a senior translator or editor. |
|
Previously Signed Off |
This is the count of words that are already translated in the Project TTKs and are marked 'Signed Off". |
|
Total |
This is the Total word count of translatable segments in the Project TTKs. |
| (c) Copyright Alchemy Software Development Ltd. |